AX-Check

SCOPE
Problemstellung
- Monkey-Audit CLI nur für Entwickler
- KMU, Agenturen und Marketing-Teams brauchen Handlungsempfehlungen
- AX muss erklärbar, teilbar und weiterverarbeitbar sein (PDF, HTML, Markdown)
- Noise Tax und Semantic Gap sind abstrakt, bis sie als Score + Maßnahmen sichtbar werden
- Systematik muss skalierbar sein: Sitemap, mehrere Routen, reproduzierbare Reports
Lösungsansatz
- AX-Check als Web-Audit auf → ax-score.monkeytribe.de
- Management Summary, Peergroup Benchmark und Handlungsempfehlung
- Vier Dimensionen → ein AX-Score (0–100) mit Teaser in ~3 Minuten
- 5 Routen aus der Sitemap — aggregiert, nicht nur Startseite
- Formate: HTML, PDF, Markdown, ZIP, Embed-Badge
- Portierung bewährter Monkey-Audit-Engine
Im Einsatz
- Nuxt/Vue
- TypeScript
- PostgreSQL
- Drizzle ORM
- Gotenberg PDF
Ergebnisse
- Produktiv unter → ax-score.monkeytribe.de
- AX-Score + Top-Befunde + Handlungsempfehlungen
- Multi-Route-Audit (5 URLs aus Sitemap) mit Site-Level-Checks
- Export: PDF, HTML, Markdown, ZIP, AX-Score-Badge
- Engine-Port aus Monkey-Audit mit Cloud-LLM-Agenten-Simulation
AX-Check: Vom Terminal-Experiment zum Web-Audit
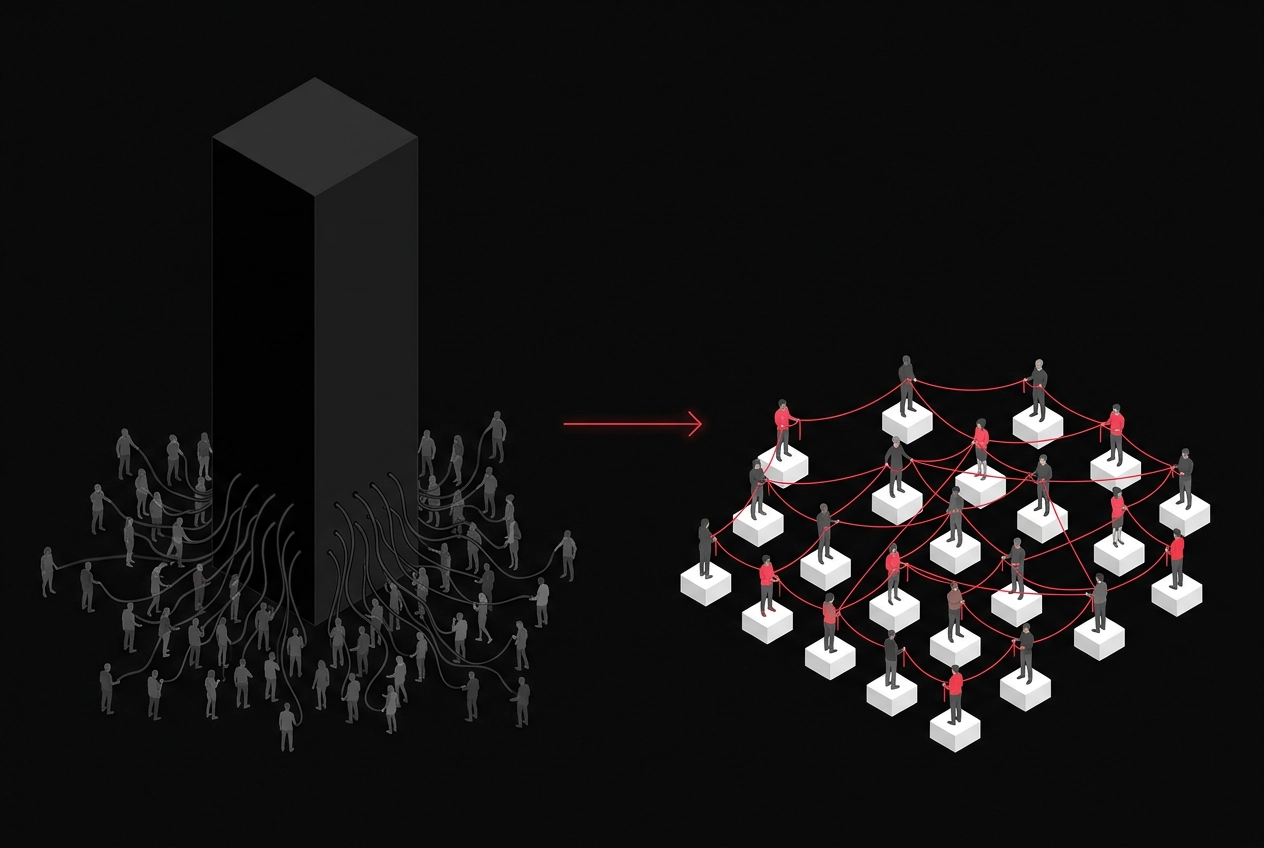
Im Januar 2026 habe ich mit Monkey-Audit begonnen, den Semantic Gap messbar zu machen — ein CLI-Tool, das Websites aus Agenten-Perspektive bewertet. In dem Artikel zur Noise-Tax-Analyse habe ich argumentiert, warum Agent Experience (AX) eine technische Konsequenz ist, wenn man den Shift von SEO zu AO betrachtet: es geht nicht nur darum, ob wir in KI-Antworten vorkommen, sondern wie präzise unsere Signale extrahiert werden.
AX-Check ist der nächste Schritt: dieselbe diagnostische DNA, aber als Web-App für Agenturen, Marketing- und Produktteams — ohne Terminal, ohne JSON-Dateien im Download-Ordner.
👉 Live testen: ax-score.monkeytribe.de
📄 Beispiel-Report: conceptmonkey.de — AX-Auswertung
AX-Check Landing
Motivation
Strukturierte Daten, semantische Hierarchien und das Signal-to-Noise-Verhältnis entscheiden zunehmend darüber, wie präzise KI-Systeme Informationen einer Website extrahieren können. Inzwischen konsumieren laut Cloudflare mehr Bots als Menschen die Web-Inhalte via HTTP-request — die Frage ist nicht mehr nur PageSpeed oder klassisches Ranking, sondern vor allem: Was kommt am Ende überhaupt im Kontext-Fenster an?
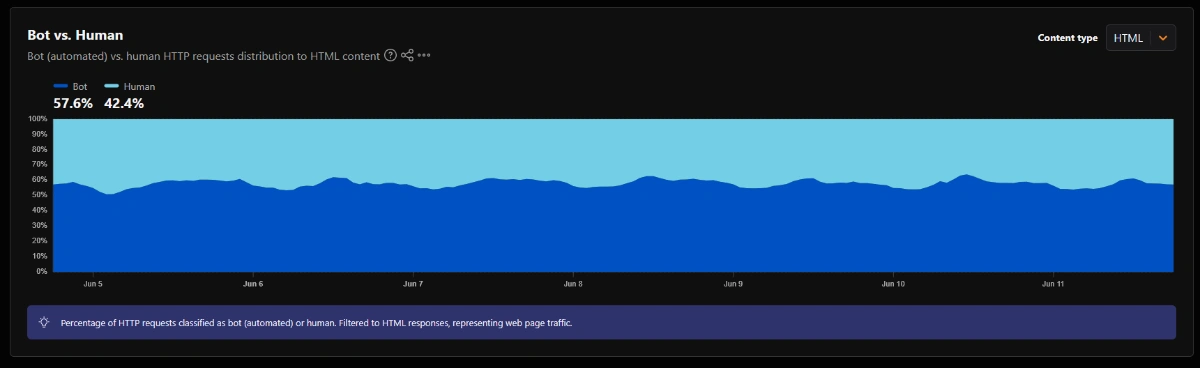
Quelle: Cloudflare Radar — Bots machen mehr http requests als Menschen
Monkey-Audit beantwortete solche Fragestellungen für mich lokal. AX-Check soll hier die Möglichkeiten ausdehnen und richtet sich and Personen / Teams, die:
- einem Kunden in Minuten einen wirklich messbaren Status zur Agent Experience zeigen wollen,
- priorisierte Befunde und Auswertungen brauchen (nicht lose Hinweise),
- den Report weiterverarbeiten wollen — im CMS, im Pitch, im Agent-Workflow.
Das CLI-Tool bleibt im Einsatz bei MonkeyLab. AX-Check ist hingegen ein öffentlich zugängliches Werkzeug, das deshalb natürlich auch als kleine Web-App gepublished wurde.
Die Methodik: Vier Dimensionen, ein Score
Der AX-Score (0–100) misst eine Agent-Experience (~ Erfahrung des Agenten bei dem Konsumieren der Seite). Diese berechnet sich aus vier gewichtete Säulen zusammen — dieselbe Logik wie bei Monkey-Audit , jedoch portiert und für Cloud-Betrieb erweitert:
| Dimension | Kürzel | Was gemessen wird | Typische Hebel |
|---|---|---|---|
| Metadaten | M | llms.txt, Schema.org, OG-Tags, robots.txt / KI-Crawler, TDM-Signale | Fehlende Agent-Orientierung, blockierte Bots |
| Signal | S | Noise-to-Signal: Störgeräusche im Verhältnis zu extrahierter Information | CSS/JS-Bloat, „Noise Tax" |
| Struktur | H | Überschriften-Hierarchie, semantisches HTML, Chunk-Tauglichkeit | H1-Sprünge, Buzzword-Dichte |
| Agenten-Simulation | A | Echte LLM-Task-Completion: Value Prop, Angebot, CTA extrahierbar? | Halluzinations-Risiko, vage Copy |
Gewichtung (mit Cloud-LLM): Metadaten 20% · Signal 25% · Struktur 20% · Agenten-Simulation 35% — weil die Live-Simulation der härteste Realitätscheck ist. Fällt das LLM aus, greift eine heuristische Proxy-Bewertung mit angepassten Gewichten.
Kritischer Sonderfall: Blockieren robots.txt oder vergleichbare Signale KI-Bots systematisch, wird der Gesamtscore stark gedämpft — das ist Absicht: Unsichtbarkeit ist ein Befund, kein Randthema. Dazu will ich erwähnen, dass es hier um die Messung des AX-Scores geht, NICHT um Sicherheitsaspekte, Schutz vor Scraping oder Bot-Zugriffen und dergleichen. Dafür müsste man ein anderes Tool bauen ;) (Kandidat für’s MonkeyLab?)
Fünf Routen statt einer Startseite
Ein Audit crawlt nicht nur /. AX-Check:
- entdeckt die Sitemap (über
robots.txtoder Standardpfade), - wählt bis zu 5 repräsentative URLs (Priorität, Aktualität),
- stellt sicher, dass die eingegebene Domain im Set ist,
- aggregiert Seiten-Scores zu einem Site-AX-Score.
So zeigt der Report nicht nur, ob die Homepage glänzt — sondern ob das System konsistent kommuniziert. Inkonsistenz zwischen Startseite und Blog-Post ist ein wiederkehrendes Muster (auch bei eigenen Audits). Die Auswertung habe ich für die Live-Version auf maximal 5 Routen begrenzt, da ansonsten eine viel aufwändigere Infrastruktur nötig wäre, mehr Worker, mehr LLM-Verarbeitung, ohne dass jedoch der Score erheblich anders würde. Dies basiert also auf einer Kosten-Nutzen-Abwägung.
Site-Level-Checks (über die vier Säulen hinaus)
Zusätzlich zur Seitenanalyse laufen modulare Site-Readiness-Checks:
- KI-Crawler-Matrix — welcher Bot darf die Daten zum Training verwenden, wer darf suchen?
- TDM / Mining-Signale — Indikatoren, keine Rechtsberatung (!)
- Mehrsprachigkeit —
hreflang-Kohärenz - Halluzinations-Risiko — Buzzword-Dichte, Spezifität, Lücke zur Agenten-Simulation
- KI-Sichtbarkeits-Vorschau — heuristische Antwortsimulation inkl. Zitations-Warnungen
Alle Befunde fließen in ein Teaser-Ergebnis und einen vollständigen Report ein — der Teaser zeigt die Top-Erkenntnisse, der Report die priorisierten Maßnahmen mit Routenbezug. Der vollständige Report kann in verschiedenen Formaten runtergeladen und auch geteilt werden. Er beinhaltet sogar ein Mini-Benchmark auf Basis LLM-extrahierter Peer-Groups.
Teaser vs Report
Landing → URL-Eingabe → Queue/Loading (~3 Min) → Teaser Ergebnis → Auswertung per E-Mail → /bericht/{slug}
| Stufe | Was der Nutzer sieht | Ohne E-Mail |
|---|---|---|
| Teaser | AX-Score, 4 Balken, Top-Befunde, Top-Empfehlungen, Potenzial (+Punkte) | ✓ |
| Auswertung | Vollständiger Report-Link nach Double-Opt-In | — |
| Report | Kapitel: Management-Summary, Befunde, Routenvergleich, Fixes, Detailanalyse, Methodik | Link teilbar |
Der Teaser beantwortet: „Wie gut sind wir?" und „Was ist der schnellste Hebel?" (z. B. niedrigste Säule Signal bei hohem Metadaten-Score — ein Muster, das bei conceptmonkey.de im Beispiel-Report gut sichtbar ist).
Die detaillierte Auswertung liefert: „Was tun wir route für route — und in welcher Reihenfolge?"
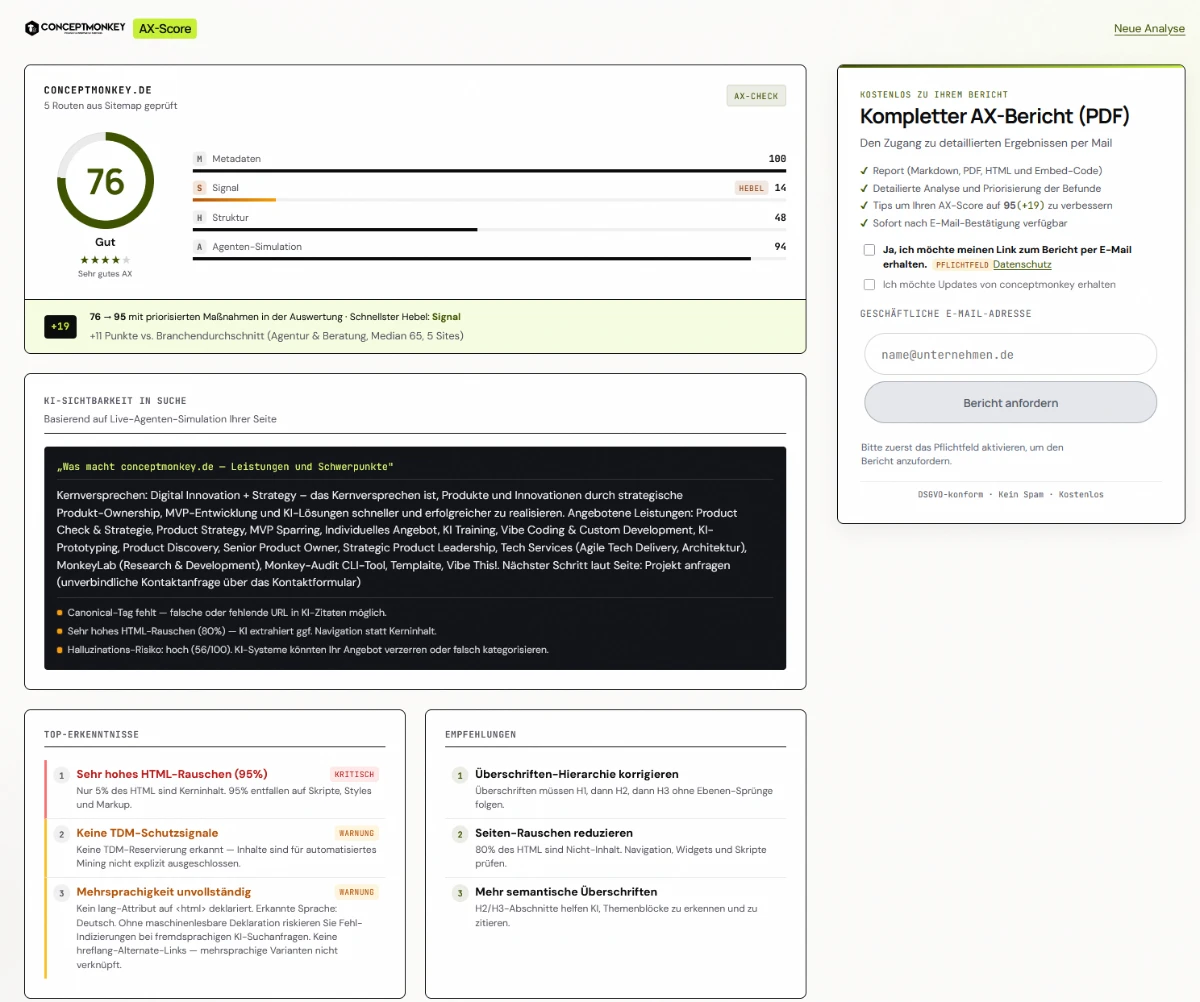
Teaser-Dashboard
Was Teams wirklich brauchen: Export & Weiterverarbeitung
Ein Score ohne Export ist ein Dashboard-Gimmick. AX-Check adressiert drei Nutzergruppen mit demselben Audit-Stand:
Für Marketing & Agentur
- PDF-Report (A4, druckfertig) — Kundengespräch, Anhang
- Teilbarer HTML-Link —
/bericht/{slug}ohne erneutes Audit - AX-Score-Badge — Embed-Code für Website oder Case Study
Für Produkt & Content
- Priorisierte Maßnahmen mit Begründung — nicht nur „SEO-Checkliste"
- Routenvergleich — wo divergiert die Kommunikation?
- Potenzial-Schätzung — z. B. „+24 Punkte machbar" mit klarer Punkte-Logik (nicht nur Prozent-Marketing)
Für Entwicklung & AI-Workflows
- Markdown-Export — maschinenlesbar, inkl. Agenten-Direktive
- ZIP-Bundle —
report.html+audit-report.md+ README - Markdown als RAG-Input — Audit-Ergebnis direkt in Coding- oder Content-Agents
Das ist der Unterschied zu „noch einem Lighthouse-Report": AX-Check liefert semantische Diagnose, nicht nur Performance.
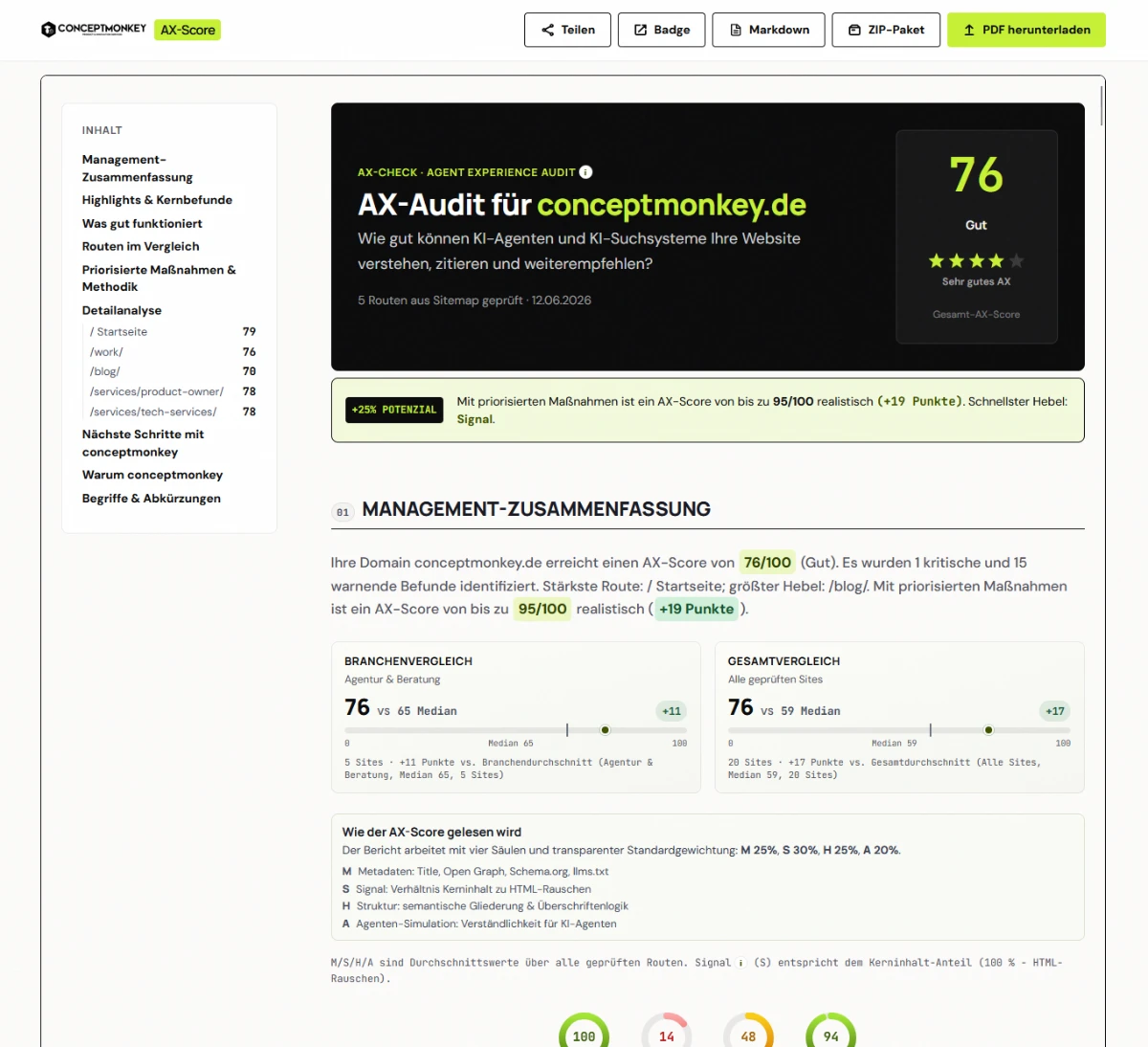
AX-Check Report mit Export-Toolbar
Technik: Vom Monkey Lab in die Produktion
Implementiert habe ich das Projekt in etwa 4 Tagen (jeweils abends), Freitags wurde das Repository vorbereitet, am folgenden Donnerstag war Launch. In diesem Projekt habe ich die Grundlagen von MonkeyAudit verwendet, um die eigentlich Algorithmen zur Messung nicht neu konzipieren und evaluieren zu müssen. Der Rest ist vollständig from Scratch etwickelt.
| Aspekt | Monkey-Audit (CLI) | AX-Check (Web) |
|---|---|---|
| Zielgruppe | Entwickler am Terminal | B2B-Teams im Browser |
| LLM | Ollama lokal | OpenRouter / aktuell via freiem Nvidia/Nemotron (Fallback: Heuristik) |
| Seiten | --deep optional | Fixes Limit: 5 Routen aus Sitemap extrahiert |
| Output | JSON / Terminal | Teaser Results + persistenter Report mit versch. Exportoptionen |
| Deploy | npx / lokale CLI | Coolify + Container (WebApp, API, Worker, Postgres) + separater Service (Gotenberg-Container) für PDF |
| Sprache | EN CLI | DE UI & Reports |
Monorepo-Struktur (Auszug):
apps/web— Nuxt App + Report-Shell (mobile Reader, Kapitel-Menü)apps/api+apps/worker— asynchroner Audit-Jobpackages/audit-core— portierte Monkey-Audit-Algorithmenpackages/report— HTML/PDF/Markdown-Rendererpackages/email— DOI + Report-Link
Die Engine ist skalierbar gebaut (Rate-Limits, Worker-Skalierung möglich, usw.), aber aktuell so klein sklaiert, dass es für mich sinnvoll bleibt. Wenn also mal Wartezeiten entstehen (bei zu viielen Analyse-Jobs) oder LLM-Latenzen, dann muss dies in Kauf genommen werden. Das Tools ist kostenfrei benutzbar und ich wollte ebenso keine zusätzlichen Kosten. Gerne biete ich aber meine Unterstützung an, sollte hier weiterer oder individueller Bedarf existieren.
Einordnung im Monkeystack
AX-Check verbindet drei Ebenen, die ich in früheren Beiträgen bereits diskutiert habe:
- Strategie — SEO vs. AO : Wo und wie sollen eigentlich welche Informationen in KI-Antworten vorkommen?
- Ökonomie & Präzision — Noise Tax / AX-ROI : Was kostet semantisches Rauschen — in Token, in Empfehlungsqualität, in Signalqualität?
- Diagnose — Monkey-Audit → AX-Check: Wie messen wir das systematisch?
Systemische Orchestrierung bedeutet hier: ein wiederholbarer Audit-Workflow, der Bias reduziert. Nicht „gefühlt gut für KI", sondern 71/100 mit Befundliste — und ein klarer Pfad zu 95/100, wenn die priorisierten Maßnahmen umgesetzt werden.
Erstes Learning aus Live-Betrieb
Signal schlägt oft Metadaten — viele Sites haben eine llms.txt oder Schema, aber auch beachtliche 95% Boilerplate-Rauschen auf ihren Seiten. Der AX-Score bestraft das nicht vollends, er macht es aber sichtbar. Extrem hohes technisches Rauschen als ‘Verpackung’ für wenig Information ist am Ende auch ein realer Kostenfaktor (Compute, Umwelt, Informationsverlust)!
Ausblick
AX-Check ist live, vermutlich noch nicht fertig. Wie angedeutet kann den Spieß auch rumdrehen und fragen, wie sicher Daten vor Fremdzugriff sind oder wie man diese verschleiern könnte. Den check könnte man beliebig weit ausbauen, aber ich schaue erst einmal, welches Feedback eingereicht wird.
Im MonkeyLabs Stack spielen viele Entwicklungen eine Rolle in einer übergeordneten Roadmap. Vielleicht werden manche Überlegungen hier nach und nach sichtbar.
Jetzt testen
Eigene Domain prüfen — kostenlos, ohne Account:
🔗 https://ax-score.monkeytribe.de
Beispiel-Auswertung (conceptmonkey.de):
🔗 https://ax-score.monkeytribe.de/bericht/tanne-jade-oodj
Fragen, Feedback oder AX-Workshop-Anfragen: über Kontakt oder LinkedIn.
Mein AX-Score vom 12.06.2026
Hier ist noch Luft nach oben … als nächstes werde ich das Markdown nehmen und versuchen meinen Score nach oben zu treiben ;)